

It's been a while since I posted my original entry and my workflow on Zettelkasten. Since then, my methods have evolved into a system that's working incredibly well for me. So, I thought I'd write about what I'm doing so others may use (and improve) my methods. This entry is an update to Zettelkasten Management 2022 using Obsidian, Drafts, and Devonthink — Workflows in Personal and Professional Productivity.
Read moreTaekman Academic Writing Workflow 2020

One of the most popular entries on WIPPP has been my 2015 Writing Workflow. My workflow has changed substantially over the last several years. I thought I'd share what I'm currently doing.
Read moreMy Migration from Papers to Bookends
I have dedicated a lot of time and energy squeaking every ounce of productivity from the Papers app. I’ve used Papers for more than a decade. Over the years, I built many scripts and work-arounds to address the shortcomings of the application.ReadCube purchased Papers in 2016. Because of the time I’ve spent in Papers, I started having angst when I read of certain changes to the software: a subscription model, the loss of Magic Citations, and the loss of integration with Scrivener.I started exploring alternatives to Papers. When I wrote about my interest in migrating away from Papers, several Wippp Readers suggested I check out Bookends. Several folks raved about the tight integration between Bookends and Devonthink as well as Bookends and Tinderbox—two other programs I use heavily in my academic life. Several people also mentioned the LEGENDARY support of SonnySoft, the company behind Bookends.My initial evaluation of Bookends was far too cursory. Following publication of the blog entry, I received a very nice email from SonnySoft asking me to take a closer look at Bookends. After digging deep into the software, I decided to migrate from Papers to Bookends. I haven’t looked back. It’s been several months now and the more I use Bookends, the more I like it.Things I like about Bookends:
The interface, although not as modern as Papers, is cleaner and more organized.
The iOS and Desktop version are better integrated than Papers.
A PDF on my phone is drop-dead easy to import into Bookends. The PDF and the metadata I choose is automatically synced with the Mac app (although I have to rename the pdf when I get to my Mac).
All PDFs are saved to a single folder in iCloud, making them easy to access and for Devonthink to index.
Bookends integrates well with Scrivener (and many other writing clients)
Dragging and dropping citations into Tinderbox and Devonthink are both seamless. Tinderbox maintains metadata from Bookends. This obviates the need for the KM script I built to move citations from Papers to Tinderbox.
Things I don’t like:
It was difficult to import Papers library with PDF into Bookends (Bookends only imported about 1/3 of my PDFs).
I can't export or customize the format of the exported metadata.
My smart collections don’t transfer to iOS.
Although I can designate a “watch” folder to import new PDFs into Bookends, this only works with PDFs that are saved to the folder AFTER Bookends is open. This didn't work well with how I collect information so I decided to modify my Hazel script, changing it to launch Bookends instead of Papers.
I don't like the way duplicate references and / or PDFs are handled.
Over the next few months, I plan to write several entries about my migration and how Bookends has become a critical part of my augmented writing workflow.
Folder Structure to Maximize Writing with Devonthink Pro
On several occasions I have written about how I use Devonthink Pro (DTP) for scholarly writing. Although at one point I had all my information on manuscripts in a single DTP database, over the last year I have maintained separate databases; one for PDFs, another for my annotations.I accomplish this by having separate folders in Dropbox. After extracting my annotations from Highlights.app, I place the exported files in their own folder. Once a month, I export all the PDFs in my Paper’s Library to their own Dropbox folder. I use a Hazel script to throw away any duplicate PDFs in the Dropbox folder. I index (not import) the annotations folder into one DTP database, and index my PDFs into another.This setup allows a fair amount of flexibility. Not only is this setup advantageous for writing with DTP (as I will cover in my next entry), it allows easy access to my PDFs for reading with Liquidtext or listening with Voice Dream.
Macsparky Video Field Guide on Hazel 4
My friend David Sparks has released a new video field guide--this time on Hazel. In true Macsparky fashion, he's delivered yet another outstanding resource. Even though I'm a seasoned Hazel user, I learned quite a few new tips and tricks--especially pertaining to the recently released Hazel 4. Pick up your copy of this and other excellent resources on the Macsparky website...and Hazel-on!
Using Hazel to Organize Grant and Manuscript Files
It is almost the beginning of February and thus I am in the throes of writing another grant (2 actually). I thought I'd take a quick break to tell you how I keep my grant information organized using Hazel.I have a folder that has a template for all the subfolders I use during the preparation of the grant. When starting my project I make a copy of this template and name the parent folder including the funding agency, the year, and the type of grant. Hazel can rename files and subfolders. I take advantage of this feature to keep the names of my files consistent.I navigate to the folder I am working on and set up new Hazel rule to rename the file and subfolders. The rule looks like this:
Hazel can rename files and subfolders. I take advantage of this feature to keep the names of my files consistent.I navigate to the folder I am working on and set up new Hazel rule to rename the file and subfolders. The rule looks like this: Anytime I put a file into a subfolder, it is automatically renamed appending the name of the grant to the end of the file. This appended name is hugely helpful when I go back to search using program such Houdah Spot or Foxtrot.
Anytime I put a file into a subfolder, it is automatically renamed appending the name of the grant to the end of the file. This appended name is hugely helpful when I go back to search using program such Houdah Spot or Foxtrot. I use the same method when I'm preparing manuscripts or working on other projects. Using Hazel I never have to think twice-every file I put into the parent folder or subfolder is appended with the name of the project.Try it out.
I use the same method when I'm preparing manuscripts or working on other projects. Using Hazel I never have to think twice-every file I put into the parent folder or subfolder is appended with the name of the project.Try it out.
Taekman Writing Workflow 2015
The early release of Papers 3 got a bad rap, and rightly so. My negative experience began as I imported my Papers 2 library into Papers 3. I had about 2500 papers, but only a fraction of these PDFs were imported properly. I am still recovering from these import problems--having to add each missing PDF by hand. Although importing was a issue early on, The makers of Papers, MekentosJ, now part of Springer Science+Business Media, worked hard to fix problems. I assume, with all the work on Papers, that importing has been fixed. My advice? Back-up your data before trying to import to Papers 3!
Although I had early problems, I can tell you that Papers 3 is pretty robust now. I recently used it to write and submit a full grant. I’ll say the app should be strongly considered if you’re looking for a reference manager / bibliography builder. If you’re interested in some of the changes in Papers 3, check out this entry.
With the release of Papers 3, all files and PDFs are bundled into a single container. Bundling makes syncing across computers more reliable, but indexing of individual files much more difficult. Unfortunatly, my Papers 2 workflow was dependent on indexing of single files. And thus, with the release of Papers 3, I had to revamp my writing workflow. That’s what I’m going to cover in this entry.
My current workflow has three parts: 1.organizing, 2. creating, and 3. writing/formatting
The software I use includes:
Papers3
DropBox
Hazel
Skim
Keyboard Maestro
Ulysses
Devonthink
Tinderbox
OmniOutliner
Scrivener
Pages or Word
Part 1: Organizing
Papers 3
Papers is used as my storehouse for all academic literature. I use Keywords and Smart Folders (akin to Smart Playlists in iTunes) to keep my literature sorted. In addition to the topic of each manuscript or book chapter, I use keywords such as "MustRead" that fuel my prioritized reading list. I tend to keep my library sorted by the date in the main window, but can easily search or sort my library in numerous other ways. My library is synchronized using Dropbox.
KeyBoard Maestro
Most people, while reading academic literature, find additional manuscripts they’d like to download. I’ve developed a series of KeyBoard Maestro scripts that simplify the download of these additional articles from Duke’s Library, Pubmed, and Google Scholar. As I’m reading a manuscript, I highlight the article I want to download and invoke my KM script. The macro copies the text string I’ve highlighted, goes to the appropriate web page (e.g. Duke’s Library), pastes the search string into the appropriate box, and hits submit. Thus with two keystrokes, I can find and download new PDFs I’d like to read. The new PDFs are sent to my “Downloads” folder. Then Hazel takes over.
Hazel
Hazel is a program that watches folders on my computer. When a file matches defined criteria, Hazel performs a script. I have a Hazel script watch for PDFs that contain the word “Reference.” When Hazel sees a file that matches, it launches Papers and imports the file into my library.
Skim
Despite the pleasing new main interface, Papers 3 highlighting leaves much to be desired. For reading and annotating scientific literature I use Skim (Skim can designated as the primary PDF reader in the Papers Prefernce menu). Skim has a robust feature set and is customized for academic literature. Oh, and it’s free! When I’m done reading and annotating, I export the Skim annotations to a PlainText file. I then use a KM script to name the the Skim Notes file to my convention.
Using another KM script, I parse the single notes file into separate text files (one for each highlight or annotation). Each file is named to convention and contains the text I highlighted in the manuscript, my own comments, and the full reference. All the individual notes are aggragated into a folder. I move this folder from my Desktop to the cloud so I can access it from anywhere. I call this my Literature Comments Folder. Now I move to Ulysses.
Ulysses
Ulysses is able to read files anywhere on my computer. I’ve configured Ulysses to point to my Literature Comments Folder so all my comments are available in an organized fashion. At this point I can add additional comments to my individual highlight files. The next step is to index the files in Devonthink.
Devonthink
Finally, I open Devonthink. This workflow has matured from what I discussed in this entry. I have a database that is solely used to index my scholarly reading. From the File Menu, I update the index (NOT import) of my Literature Comments Folder. Indexing this folder allows me to take advantage of the “Artificial Intelligence” of Devonthink, finding relevant information throughout my reading.
Part 2: Creating
Tinderbox
At this point I’m ready to start developing my scholarly work. I use Tinderbox (in Outline View) to generate a high-level preliminary outline. Tinderbox is a power-user’s application. I’ve only scratched the surface of its capabilities, but find it extremely useful early on to organize thoughts and find connections between what I’ve read and what I hope to write.
From within Devonthink, I review each of my comments. If I find something I want to include, I drag and drop the file (comment, reference, and highlighted text) into Tinderbox. Then, using Devonthink’s “See Also & Classify” command, I see related notes in my Literature Comments Folder . I drag and drop the additional comments into Tinderbox too. As I think of new ideas, it’s not uncommon for me to conduct a freeform search from within Devonthink to see which comments bubble to the top.
Once I have several dozen comments in Tinderbox, I find myself entertaining new thoughts, and often adjusting (or add to) my outline.
Another way I approach the creative process is to surf through interesting comments and move them one by one into Tinderbox without organizing them (usually in the Map View). Once I have a few dozen of these interesting quotes and highlights, I start to see connections between them, letting me further refine and organize my thoughts (and begin to develop and outline).
Once I’m satisfied with my outline, I’ll sometimes export to OmniOutliner for additional organization. But most times, I’ll export my outline directly from Tinderbox to Scrivener.
Part 3: Writing and Formatting
Scrivener
Scrivener is the place where the early versions of my manuscript are built. Scrivener imports OPML files from Tinderbox or OmniOutliner—each bullet of the outline gets its own content field. I do the majority of my early writing in Scrivener, attacking whatever section I feel like writing at the time. I use the Magic Citations of Papers 3 to insert my references as I write. Once I get words down on the screen, I often find myself tweaking the outline in Scrivener. This early phase, when I’m writing on the go, is when I yearn for the iPad version of Scrivener. Until that’s available, I’ll continue to use Scrivener’s synchronization with SimpleNote when I plan to write on my iPad.
When I’ve completed all the sections in my Scrivener outline, I’ll export everything I’ve written to Ulysses. I use Ulysses to edit and rewrite (in Markdown) until I think the work is ready for submission. As I’m importing and editing my paper in Ulysses, I make sure to have the document type set to Markdown (not MarkdownXL). MarkdownXL uses the curly brackets as an internal mark for annotations. If I use MarkdownXL in Ulysses, all of my Papers citations are formatted as footnotes—very annoying.
Word or Pages
I write and edit for several rounds in Ulysses. Ulysses for iPad makes this process more seamless and enjoyable. Unfortunately, when I’m done writing, I cannot format my bibliography in Ulysses. I have to export my file to Word or Pages. That’s okay though, I still have to format my paper. I use an old version of Pages (the new version of Pages still doesn’t allow bibliography formatting). Microsoft Word also works. To do this, I highlight all my text and from the Ulysses Edit Menu I select Copy as RTF (Word), then paste it in the word processing application. After my bibliography is formatted, I format the rest of the paper.
Finally, as the final check of my writing, I use a KM script to read back the text to me. I often find errors, even in this late phase of writing. Finally, I double check everything conforms to required format of the journal (or funding agency) and hit submit.
And there you have it: my writing workflow. As with most of my workflows it is continuously subject to improvement. For the time being this workflow has streamlined my writing. I hope it works for you too.
Writing and Reading Workflow: Batching and Automating Full-Text Retrieval
In my work at Duke University on simulation, games-based learning, and learning technology, I frequently read and write scientific information. I’ve developed a series of workflows to help me efficiently deal with information when writing papers and grants. In a previous entry I talked about how I try to batch operations, doing similar things at the same time. This entry will be about my workflow for reading scientific manuscripts.
I use Skim for scientific reading, typically using the bottom pane of the “Split PDF” feature to look at the title of references as I come across them in the body of the manuscript. On average, I’m interested in downloading about 10% of these references to my personal library.
Although I love Skim, one feature I have not been able to figure out is how to highlight items in the bottom split screen. Thus, I’ve created a workaround. Before I start reading an article in Skim, I create a note called “Get Manuscripts” As I’m reading, I merely record the references number of articles I want to fetch in my “Get References” note. Because I create this note first it’s always located at the top of my Skim Notes. When I’m done reading the current article and processing my annotations, I retrieve the supporting articles I identified while reading.
To do this, I use a phenomenal program called KeyBoard Maestro. Keyboard Maestro lets me type a single keyboard command to trigger an entire workflow. One by one, I work through my “Get References” numbers, highlighting the title of each corresponding article. After highlighting each title, Keyboard Maestro does the rest (invoked by Command-Option-R).
Keyboard Maestro automatically (1) copies my highlighted text, (2) surfs to the Duke Library literature search page, (3) pastes the text string into the appropriate field, and (4) submits the search. Thus, with a single key combination, I am able to download the full text of supporting literature. Once I find the full text I'm interested in (usually a PDF), I save it to my Download Folder, where Hazel takes over and imports the paper into my Papers Library.
If I'm not ready to retrieve the articles, I create an Omnifocus Action for each to be collected at a later time.
My macro is not limited to Skim, it works with any text I’ve highlighted, be it on the web, in a manuscript, or somewhere else. Here is a picture of the programming, but obviously, you’ll have to modify it for your own favorite full-text repository. Enjoy!

Addendum (January 14, 2014): If you’re searching at Duke, you’ve probably noticed the library changed its search interface. I’ve updated the Keyboard Maestro Script accordingly. It’s only configured to search for peer-reviewed articles. Download the script and import it into Keyboard Maestro (will only work for Duke Libraries).
Writing Workflows: Collecting Information in Papers2 (MacPowerUsers Show 100)
I had a great time as a guest on David Sparks and Katie Floyd’s milestone MacPowerUser Show 100 yesterday. Their podcast has been a staple on my iPod and iPhone for years. To celebrate they invited 10 guests to discuss workflows in their professional lives. Over the past several years, I have learned an incredible amount from Katie and David. It was nice to be able to give something back.I had the pleasure of discussing a portion of my writing workflow–how I get information into my academic research library-Papers2. I’ve talked about why I use Papers in a previous entry. If you’re not familiar with Papers you should read my previous post first. Go ahead. I’ll wait.——————————- Okay, welcome back.When tackling a new writing project I pass through several stages:
- collecting
- organizing
- reading
- synthesizing
- citing
The workflow I covered on the MacPowerUsers had to do with collecting information. I usually obtain scientific literature in one of three ways:
- as a recipient of an Endnote library (when writing collaboratively)
- through personal searches on the web
- as an attachment to a colleague’s email.
I’ll cover each of these contingencies below.Endnote still has quite a foothold in academics. I often find my collaborators have not yet made the switch to Papers. Many times, when writing collaboratively, we must share libraries between the two applications (Endnote and Papers). Fortunately Papers can import (and export) Endnote libraries seamlessly (as long as they’re in Endnote XML format). Easy and no need for a workflow!However, the other two situations are more complex (searching myself or receiving attachments to emails) and require a workflow–making use of the wonderful program called Hazel. Hazel monitors folders on my computer and acts on individual files according to rules I create. Hazel can even peek at the content of files and “recognize” what's inside. I have Hazel monitoring about a dozen folders on my Mac, but my Downloads Folder keeps Hazel the busiest. I have about two dozen rules running on my Downloads Folder alone.For this particular writing workflow I ask Hazel to look at the contents of every PDF in my Downloads Folder and match files that have words unique to scholarly publications. I’ve found having Hazel search for the word “References” within each PDF works the best. When a PDF whose contents contain the word “References” is matched, Hazel automatically launches Papers and imports the manuscript. While importing, Papers fetches metadata, renames the PDF to the convention I’ve specified, and files the manuscript in a specified hierarchy on DropBox–all automatically. Another preference in Papers erases the original file once it’s imported.
I’ve found having Hazel search for the word “References” within each PDF works the best. When a PDF whose contents contain the word “References” is matched, Hazel automatically launches Papers and imports the manuscript. While importing, Papers fetches metadata, renames the PDF to the convention I’ve specified, and files the manuscript in a specified hierarchy on DropBox–all automatically. Another preference in Papers erases the original file once it’s imported.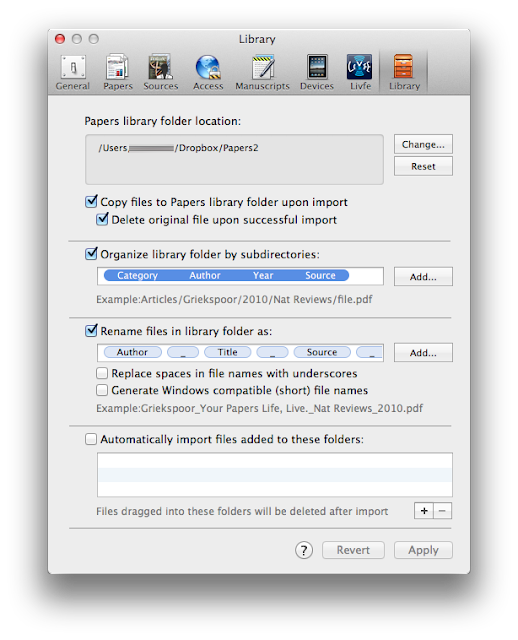 I’ve tried other search words for Hazel including “abstract,” “methods,” “results,” and “discussion”–none work as well as references. Most every scholarly manuscripts has references (unfortunately, even the word “references” will not be 100% reliable–in a minority of publications, references will be called a "bibliographies" or "citations").You are probably wondering why I don’t just use the built in unified search window in Papers. My answer: it is faster and less frustrating to find full-text directly through our Library’s web page. Papers unified search will work through a fire wall (using proxy URLs in the search interface) – but it’s hit-or-miss whether a link in Papers will lead to a full-text article or merely a frustrating publisher’s login screen–most usually the latter. My hit rate is much higher on the web. I use Papers built-in search engine primarily to retrieve metadata (after the full text pdf has already been imported).When I’m collecting full-text articles I save EVERYTHING to my Downloads Folder and let Hazel do the rest. When she finds a match, she launches Papers and imports each manuscript without any additional effort on my part. Using this method, I can conduct my search for scholarly information with minimal interruptions - Hazel does the rest.Searching on my own is the most common way I get information into papers, but occasionally a colleague will mail me something they think I should read. For these situations here’s what I do. I have Hazel monitor my Mail Downloads folder (~/Library/Containers/com.apple.mail/Data/Library/Mail Downloads ) and copy EVERY attachment to my Downloads Folder (I do this for a host of reasons–not just publications–I’ll talk about why in a future entry) Once the paper is in the Downloads folder Hazel can work her magic using the rule mentioned earlier. Apple now hides the Library Folder by default. Here is a quick tutorial on how to find it on your hard drive (works for Lion or Mountain Lion).
I’ve tried other search words for Hazel including “abstract,” “methods,” “results,” and “discussion”–none work as well as references. Most every scholarly manuscripts has references (unfortunately, even the word “references” will not be 100% reliable–in a minority of publications, references will be called a "bibliographies" or "citations").You are probably wondering why I don’t just use the built in unified search window in Papers. My answer: it is faster and less frustrating to find full-text directly through our Library’s web page. Papers unified search will work through a fire wall (using proxy URLs in the search interface) – but it’s hit-or-miss whether a link in Papers will lead to a full-text article or merely a frustrating publisher’s login screen–most usually the latter. My hit rate is much higher on the web. I use Papers built-in search engine primarily to retrieve metadata (after the full text pdf has already been imported).When I’m collecting full-text articles I save EVERYTHING to my Downloads Folder and let Hazel do the rest. When she finds a match, she launches Papers and imports each manuscript without any additional effort on my part. Using this method, I can conduct my search for scholarly information with minimal interruptions - Hazel does the rest.Searching on my own is the most common way I get information into papers, but occasionally a colleague will mail me something they think I should read. For these situations here’s what I do. I have Hazel monitor my Mail Downloads folder (~/Library/Containers/com.apple.mail/Data/Library/Mail Downloads ) and copy EVERY attachment to my Downloads Folder (I do this for a host of reasons–not just publications–I’ll talk about why in a future entry) Once the paper is in the Downloads folder Hazel can work her magic using the rule mentioned earlier. Apple now hides the Library Folder by default. Here is a quick tutorial on how to find it on your hard drive (works for Lion or Mountain Lion). So there it is: how I use Hazel to speed up the collection of information when writing or researching. I hope it’s helpful to you. In a future entry I’ll talk about an emerging trend in research paper management: social networking.Cheers, Jeff
So there it is: how I use Hazel to speed up the collection of information when writing or researching. I hope it’s helpful to you. In a future entry I’ll talk about an emerging trend in research paper management: social networking.Cheers, Jeff